您现在的位置是:主页 > 科技圈快讯 > 好文 >
中国首款770亿晶体管通用GPU芯片——壁仞科技BR100首次展示海外!
发布时间:2022年08月23日 22:59:38 好文 人已围观
简介8月9日,壁仞科技正式发布了BR100系列通用计算GPU,宣称其算力在国内处于领先地位,并在多个指标上与国际顶尖产品相媲美或超越。随后在8月22日,第34届Hot Chips芯片大会的首日演讲中...
在8月9日,国内的科技创新公司壁仞科技(Birentech)推出了BR100系列通用计算GPU,声称其算力在国内处于领先地位,多项指标甚至达到或超过国际顶级产品。
8月22日,当地时间,第34届Hot Chips芯片大会的首日,NVIDIA Hopper、AMD Instinct MI200、Intel Ponte Vecchio三大巨头的通用GPU相继亮相,而壁仞科技的BR100也与它们一同展现实力。
会议上,壁仞科技的联合创始人兼CTO洪洲,以及联合创始人兼总裁徐凌杰进行了以“Biren BR100 GPGPU: 加速数据中心规模的AI计算”为题的演讲,向来自全球的专业听众讲解了BR100芯片的特性和其创新架构的细节。

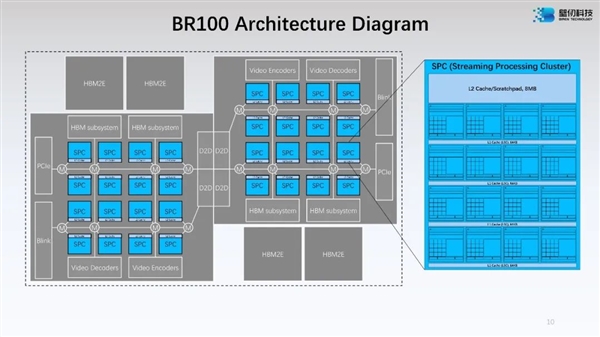
据介绍,BR100是一款专门用于加速数据中心大规模通用计算的GPGPU芯片,具备极高的算力密度,单个显卡在16位浮点计算上可达到PFLOPS级别,且拥有快速的片上及片外互联带宽。
BR100采用7nm工艺、Chiplet小芯片设计,并运用了CoWoS 2.5D封装技术,可以通过OAM模组形态部署,允许在通用UBB主板上实现8卡点对点的完全互连拓扑。
为支持强大的计算能力,BR100配有超过300MB的片上高速缓存,便于存储和重用数据,并配备64GB的HBM2E高速内存。
其核心计算单元由众多通用流式处理器构成,具备通用计算能力,以及基于2.5D GEMM架构的专用张量加速算力。

在架构创新方面,壁仞科技特别考虑到深度学习等通用负载的计算特性,提供了一系列针对数据流的增强功能,包括特有的C-Warp协同并发模式、张量数据访问加速器TDA、NUMA/UMA访问模式、近存储计算等。这些功能使得BR100在算力和能效比上达到国际领先水平。
此外,壁仞科技还推出了一种新的TF32+数据类型,具备比传统TF32更高的精度。

在软件方面,壁仞科技还展示了BIRENSUPATM软件栈,其核心编程模型提供了类似于C/C++的编程接口与运行时API,风格与主流GPGPU开发语言和编程模式相近。
这使得开发者能够轻松地在BR100上进行编程,同时显著减少代码迁移的工作量,实现从主流开发环境到BIRENSUPA平台的无缝过渡。

资料显示,壁仞科技BR100集成了多达770亿个晶体管,其规模可与人类大脑的神经细胞相媲美,已经非常接近NVIDIA GH100计算核心的800亿晶体管,并且BR100系列芯片成功一次点亮!
相关文章
随机图文

ARM 推出 Cortex-A78:5nm 工艺,CPU 性能升
ARM 公司推出新一代 CPU 架构 Cortex-A78,适用于 5nm 工艺,性能提升 20%,功耗降低...
华为 Mate 40 Pro 4G 版官宣降价,5599 元起售
华为 Mate 40 Pro 因芯片等原因缺货已久,去年 6 月推出 4G 版,该版本与 5G 版硬件...
苹果 iPhone 15 或采用自研基带,信号表现
从 iPhone 7 起苹果部分机型采用 Intel 基带,iPhone XS 到 iPhone 11 基本全系 Intel 独占...
IP 显示功能让“海外”网红现形,“梅西
近日,各大社交平台上线强制开启且无法关闭的 IP 属地功能,不少网红博主的...