
您现在的位置是:主页 > 品牌 > 微软 >
3秒内复制任何声音!微软音频版DALL·E惊人技术 甚至连环境音效都能重现
发布时间:2023年01月11日 13:52:13 微软 人已围观
简介微软最新推出的语音合成模型VALL·E,能够在仅需3秒钟的语音样本基础上,完美模仿任何人的声音。这一技术引发人们对声音复制的担忧,背后隐含着细思极恐的潜在风险。...
仅需3秒钟,一款从未听过你声音的人工智能便能精准重现你的声线。
这是否让人感到不寒而栗?
这是微软最新发布的AI技术——VALL·E语音合成模型,它能够通过3秒的语音样本,复制任意个体的声音。
这项技术源于DALL·E,但专注于音频合成,发布后在网络上迅速走红:
有网友表示,如果VALL·E与ChatGPT联用,效果将会惊人:
不久的将来,我们或许能在Zoom上与GPT-4畅聊。

还有人幽默地说道,在AI已经征服了作家和画家的领域后,配音演员恐怕也逃不过这股浪潮。

那么,VALL·E是如何在3秒内模仿一个“未接触过”的声音的呢?
运用语言模型解析音频
它通过“零样本学习”的方式,基于AI创造“从未听过”的声音。
虽然语音合成技术已日臻成熟,但早前的零样本合成效果并不理想。
常规的语音合成方法多采用预训练与微调的方式,若应用于零样本场景,往往会导致生成语音的自然度和相似度较差。
鉴于此背景,VALL·E应运而生,标新立异,对比主流的语音模型引入了新的思路。

与传统模型通过梅尔频谱提取特征不同,VALL·E将语音合成视为语言模型任务,前者为连续,后者则为离散化处理。
具体来说,传统的语音合成通常遵循“音素→梅尔频谱(mel-spectrogram)→波形”的流程。
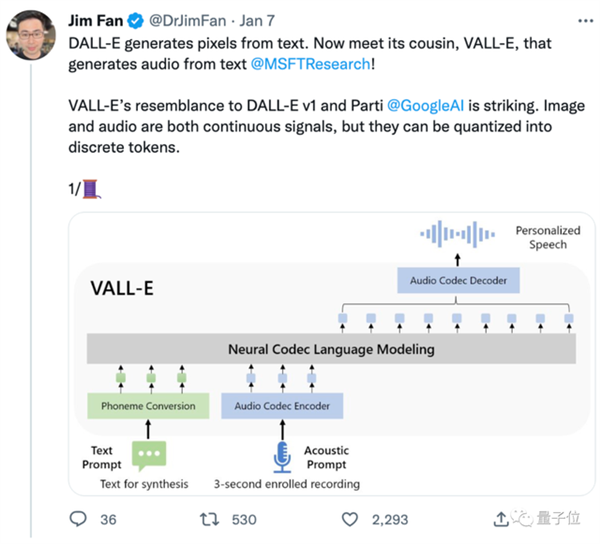
而VALL·E则改变为“音素→离散音频编码→波形”的模式:
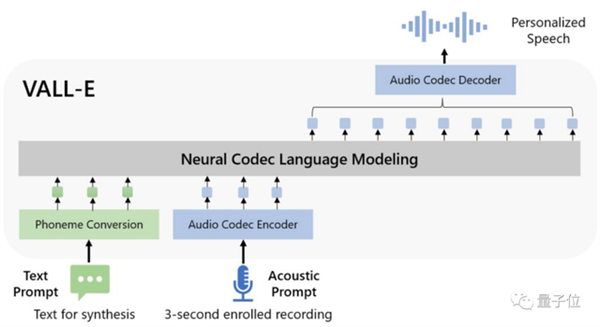
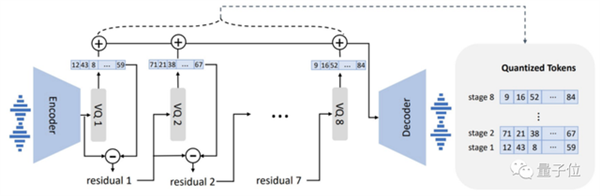
在模型设计上,VALL·E类同VQVAE,将音频量化为一系列离散的tokens,其中首个量化器负责捕捉音频内容和发言者的身份特征,而其余量化器则用于细化信号,使其听起来更为自然:
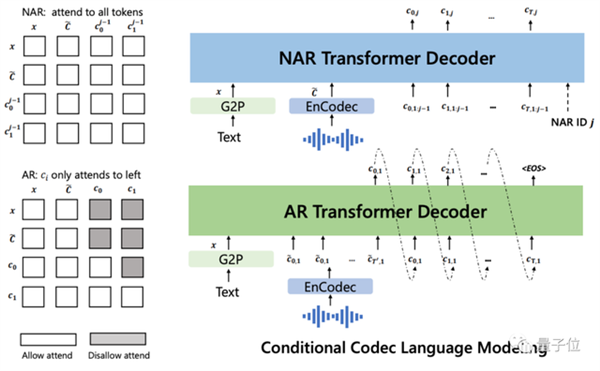
接着,结合文本和3秒的音频提示,自回归地输出离散音频编码:
VALL·E的功能十分全面,除了零样本语音合成外,还支持语音编辑及结合GPT-3进行的语音内容创作。
那么,VALL·E在实际效果上表现如何呢?
连环境音都能精准重现
根据生成的语音效果显示,VALL·E不仅能完美还原说话者的音色。