
您现在的位置是:主页 > 品牌 > 微软 >
OpenAI与微软陷入困境,网友称这是AI侵权的历史性事件!
发布时间:2023年12月28日 17:47:03 微软 人已围观
简介OpenAI正面临一场可能是历史上最复杂的AI版权诉讼。《纽约时报》向地方法院提交了一份包含220,000页附件的状书,其中列举了多达100个证据,指控ChatGPT生成的内容与《纽约时报》的新闻...
OpenAI当前可能正在经历史上最具挑战性的AI版权诉讼。
《纽约时报》作为原告,提交了一宗包含220,000页材料的诉讼文件给地方法院。
诉状中有一个部分列出多达100条明确证据,显示ChatGPT生成的内容与《纽约时报》的报道几乎完全相同:

这一事件迅速引起广泛关注,让OpenAI感到措手不及。公司发言人回应道:“对此发展实在是始料未及。”
他们在感到意外与失望的同时,表示“希望能找到双方都能接受的合作方案,就如与其他多家出版商所做的那样。”

微软同样是被告之一,或许这次两家公司无法像此前那样与其他出版商轻松和解。
《纽约时报》要求OpenAI和微软销毁包含侵权材料的模型与训练数据,并为非法复制及使用《纽约时报》作品所造成的“数十亿美元的法定和实际损失”承担责任。
《纽约时报》并非首家因知识产权争议起诉生成式AI公司的出版机构,但无疑是目前参与此类诉讼中最大的出版商之一,同时拥有丰富的证据和坚强的律师团队。
网友们普遍感慨这将是一个“见证AI侵权的重要案例”:

律师网友@Cecilia Ziniti在分析诉状后指出,“这是迄今为止针对生成式AI的最佳侵权指控案例。”:
这起案例有什么值得关注的地方呢?
“可能成为AI侵权的标志性案件”
Cecilia Ziniti分析了对OpenAI不利的几个主要因素:
有证据证明《纽约时报》的文章是用于训练AI的一个完整数据集;证据清晰明确;其深度报道展现了创造力;投诉书将OpenAI描绘为以盈利为导向的公司,而媒体行业则具有公益性;模型产生幻觉,捏造虚假信息;以及强大的法律支持。
接下来我们逐一探讨。
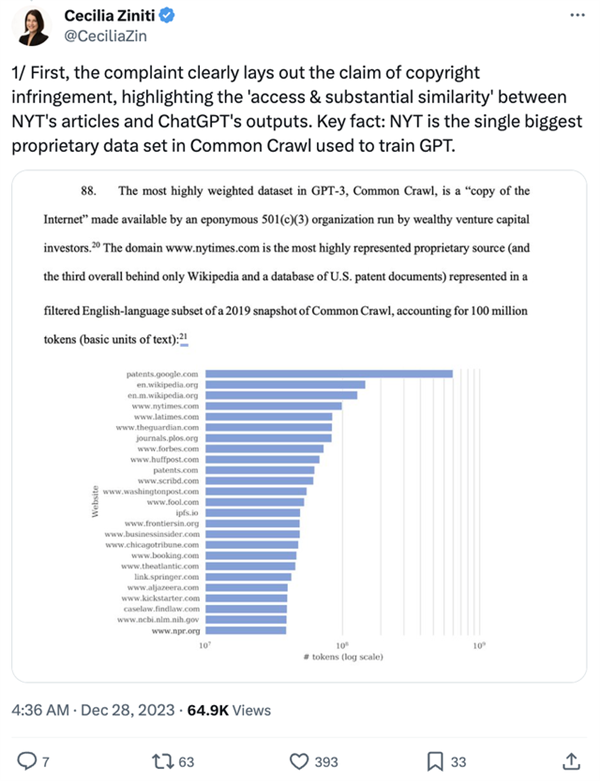
首先,这份投诉文件清晰地表明了版权侵权的指控,强调了《纽约时报》的文章与ChatGPT生成的内容之间存在“获取与实质性相似性”。
关键事实是:《纽约时报》的文章构成了用于训练GPT的Common Crawl(一个抓取互联网数据的开放平台)中最大的专有数据集。
其次,诉状中抄袭的证据在视觉上非常突出,被复制的文本标记为红色,而GPT生成的新词则为黑色,这样的对比会显著影响陪审团的判断。