
您现在的位置是:主页 > 科技圈快讯 > 最新 >
国产AI巨头DeepSeek:6710亿参数训练仅需10%算力,震撼业界!
发布时间:2024年12月27日 12:51:31 最新 人已围观
简介DeepSeek新版模型V3正式发布,引起技术界广泛关注。该版本不仅延续了以往的经济实用特点,还实现了完全开源,详细阐述了训练细节,提供了53页的研究论文。行业人士对其评价备受期...
DeepSeek的新版本模型迎来了正式发布,科技界的精英们对此反应热烈!
在保持高性价比的基础上,DeepSeek V3发布后完全开源,其培训细节在53页论文中详细披露。

无需多说,QLoRA初步评价其一词:优雅。
更具体地说,DeepSeek V3是一个拥有671B参数的MoE模型,激活量为37B,经过14.8T高质量token的预训练。
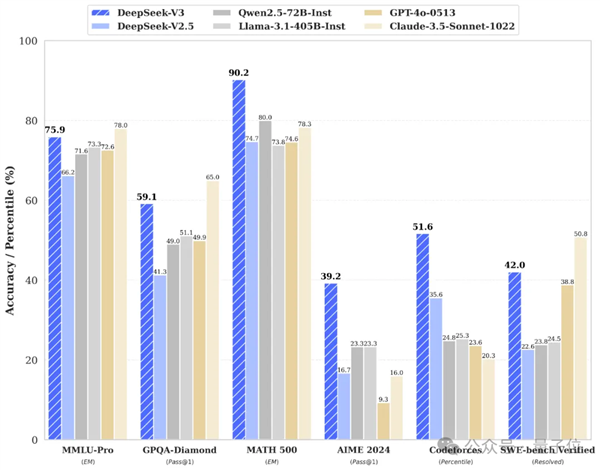
在多重评测中,DeepSeek V3达成开源SOTA,力压Llama 3.1 405B,能够与GPT-4o、Claude 3.5 Sonnet等顶级模型竞争——
其价格仅为Claude 3.5 Haiku的9%,相比Claude 3.5 Sonnet更显经济。
更为重要的是,论文中显示出了不少关键细节:
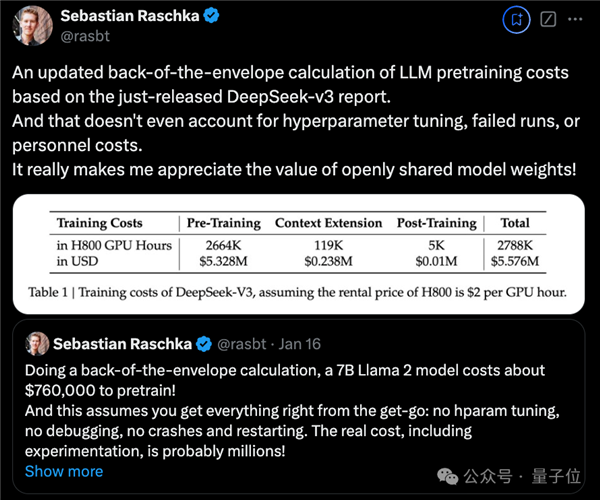
DeepSeek V3的整个训练流程耗时不到280万GPU小时,相较之下,Llama 3 405B 的训练时间则达到了3080万GPU小时(注意,GPU型号也有所差异)。
在成本上对比,训练671B的DeepSeek V3花费557.6万美元(约4070万人民币),而仅训练一个7B的Llama 2则需76万美元(约555万人民币)。
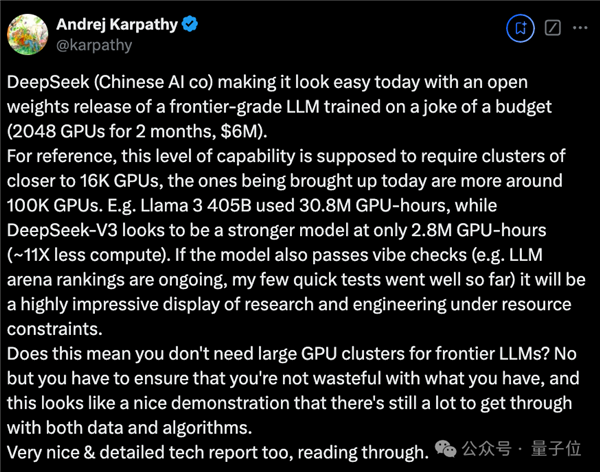
OpenAI的创始成员Karpathy对此表示赞赏:
DeepSeek V3让在有限计算能力下进行模型预训练成为了可能。
DeepSeek V3的性能看似超越了Llama 3 405B,训练所需算力却仅为后者的1/11。
Meta的研究员田渊栋对DeepSeek V3的训练过程感到惊叹,称其为“黑科技”:
这真是伟大的成就。
全网对其进行热烈实测
首先看看官方的观点,新模型关键具有以下特点:
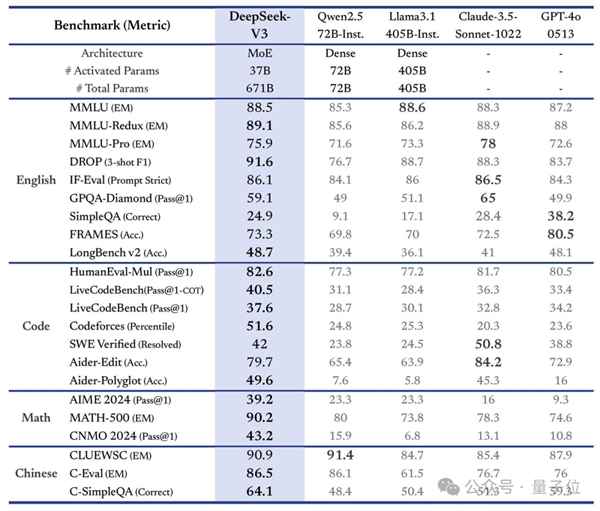
从模型性能来看,其评测分数不仅超越了Qwen2.5-72B和Llama-3.1-405B等开源模型,甚至与一些顶级闭源模型(如GPT-4o及Claude-3.5-Sonnet)相媲美。
从具体响应速度来看,该模型生成速度提升至每秒60个tokens,速度提高了3倍。
在提升速度与质量的同时,DeepSeek V3的API费用也大幅降低。
每百万输入tokens为0.5元(缓存命中)/ 2元(缓存未命中),每百万输出tokens为8元。


