
您现在的位置是:主页 > 品牌 > 阿里巴巴 >
阿里推出32B大模型开源:我们迅速评测“弱智吧”
发布时间:2024年04月07日 18:28:27 阿里巴巴 人已围观
简介阿里推出了通义千问(Qwen)系列的最后一部分——Qwen 1.5-32B的正式开源。官方展示了其在竞争中的“成绩单”,并介绍了与之同台竞技的参与者。此次开源标志着Qwen系列的进一步发展和...
阿里巴巴的通义千问(Qwen)项目,终于完善了1.5系列的最后一个部分——
正式开源的Qwen 1.5-32B。

接下来,直接来看“成绩单”。
此次官方选择了Mixtral 8x7B模型与同样属于Qwen 1.5系列的72B模型进行对比。
从评测结果来看,Qwen 1.5-32B在多个指标上已经超越或持平于Mixtral 8x7B:
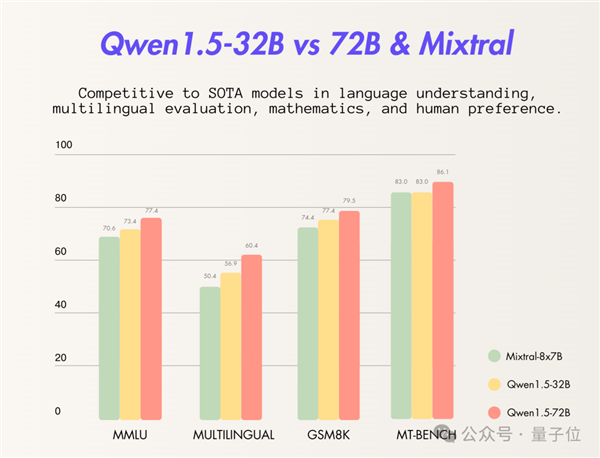
而且,即便是在与自家更高参数模型的比较中,Qwen 1.5-32B依然在“小体量、大性能”的策略下展现出了出色的表现。
通义千问团队的成员指出:
该模型在语言理解、多语种支持、编码以及数学处理等方面的性能与72B模型相当。
而在推理与部署时,使用成本更为友好。

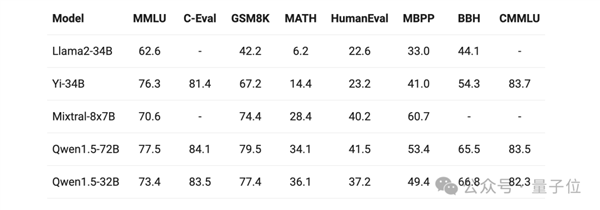
此外,即使引入其他参数相当的大模型进行对比,Qwen 1.5-32B在多项评测中的表现依然出色:
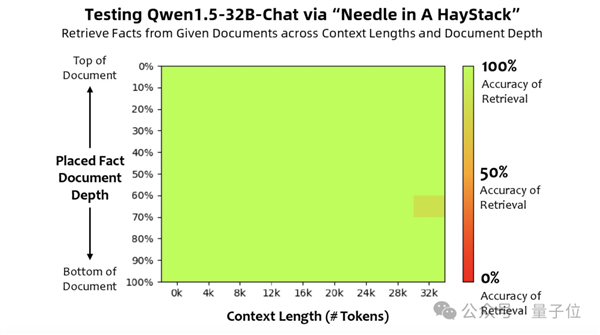
此外,团队还进行了一个颇具趣味的测试——长文本评估任务,“大海捞针”。
这个任务大致是将一个与文本无关的句子(“针”)隐藏于大量文本(“大海”)中,并通过自然语言提问的形式,观察AI能否准确提取出该句子。
结果显示,Qwen 1.5-32B在32k tokens的上下文中表现良好。
然而,之前展示的仅仅是Qwen 1.5-32B在评分中的成绩,那实际使用效果又如何呢?
进行一场“弱智吧”的挑战
自从大模型引起热潮后,“弱智吧”便成为了评测大模型逻辑能力的一大标准,被戏称为“弱智吧基准测试”。
(“弱智吧”来源于百度贴吧,因其充满离奇荒谬评论而著称的中文社区。)
就在前几天,“弱智吧”还出现在一篇重要的AI论文中,被认定为最佳中文训练数据,引发了广泛讨论。
这一研究由中科院深圳先进技术研究院、中科院自动化研究所以及滑铁卢大学等多所高校和研究机构联合完成。

正巧,Qwen 1.5-32B在开源的同时,也发布了在线体验demo,那么两者结合会产生怎样的效果?
我们来看第一道题: