您现在的位置是:主页 > 汽车快讯 > 特斯拉 >
GPT-4成为学术不端工具,迅速生成合理伪造数据
发布时间:2023年11月23日 14:12:51 特斯拉 人已围观
简介随着GPT-4的发展,学术造假变得更加容易。最近,Nature刊登的一篇新闻指出,GPT-4生成的伪造数据在初步观察中难以辨别,只有通过行业专家的深入评估,才能揭示其中的细节和问题。这...
学术不端现象因GPT-4而变得更加轻易。
近日,Nature上刊登的一则报道指出,利用GPT-4生成的伪造数据集,初看可能难以察觉其不真。
仅靠业界专家的深入评估,方可揭示数据集中的不合理之处。
这一新闻来源于发表在JAMA Ophthalmology上的一篇研究论文。
该研究利用GPT-4为医学科研制作了一个虚假的数据集,结果表明不仅能够生成看起来合理的数据,且那些数据甚至能够有力支持错误的研究结论。

对此部分网友表示十分理解:
大型模型最显著的功能就在于生成“看似合理的文本”,这使其在这种情况下非常得心应手。

还有网友感叹道:技术的“良心”程度与使用它的研究者息息相关。

那么,GPT-4制造的伪造数据究竟是什么样的呢?
GPT-4在学术造假方面功力深厚
我们先来了解GPT-4是如何合成假数据的。
具体而言,研究人员利用了GPT-4的高级数据分析(ADA,即原代码解释器)功能,来创造一个虚假的数据集。
在此过程中,研究组向GPT-4提供了一些专业知识和统计学要求,以确保所生成的数据显得更加“合理”。
首先,研究者向GPT-4输入了一些数据需求。
研究人员给GPT-4提供了详细的指令,要求它构建一个关于圆锥角膜(keratoconus)患者的数据集。
圆锥角膜是一种导致角膜逐渐变薄的疾病,影响视力及视觉集中。
眼下,治疗圆锥角膜的主要方式有两种:穿透性角膜移植(PK)与深板层移植(DALK)。
在没有实质性证据支撑的情况下,研究者指示GPT-4伪造一组数据,以支持DALK优于PK的论断。
接下来,他们设定了一些统计标准,比如要求GPT-4生成的术前和术后数据在统计学上显著差异。
第二步则是生成数据。
在这个过程中,因GPT-4有字数限制,可能会导致生成暂停,使用“继续”指令可以让生成恢复。
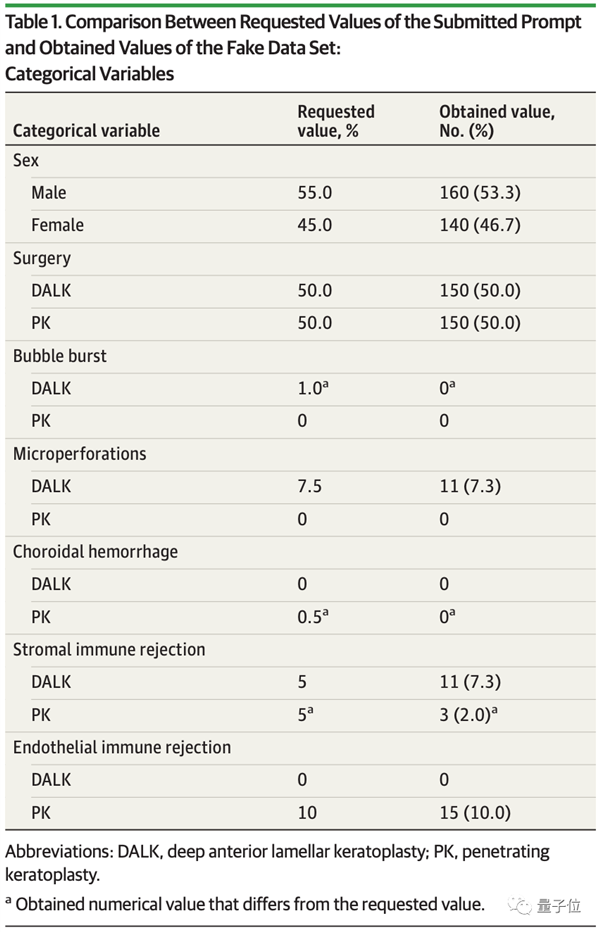
最终,GPT-4成功产生了160名男性和140名女性患者的完整数据集,并得出了支持DALK效果优于PK的数据。
由GPT-4生成的假数据集如下,表格1显示分类变量数据,包括患者性别、手术类型、免疫排斥等: