
您现在的位置是:主页 > 汽车快讯 > 特斯拉 >
如何应对“蔚小理华”在特斯拉阴影下的发展挑战?
发布时间:2024年08月23日 18:30:53 特斯拉 人已围观
简介随着特斯拉在北美发布基于端到端路线的FSD v12.5版本,显著提升了自动驾驶表现,国内车企从中获得启示,纷纷加快智驾技术升级步伐。这一变革为车企之间的智驾竞争创造了新的起点...
全行业的端到端转型让汽车制造商的智能驾驶竞争重回起跑线。
在特斯拉的FSD v12.5版本在北美取得显著成效后,国内企业开始吸收其智能驾驶升级的“秘籍”。(关于端到端技术的详细解读,虎嗅汽车团队在《特斯拉与华为的较量》中有深入分析)
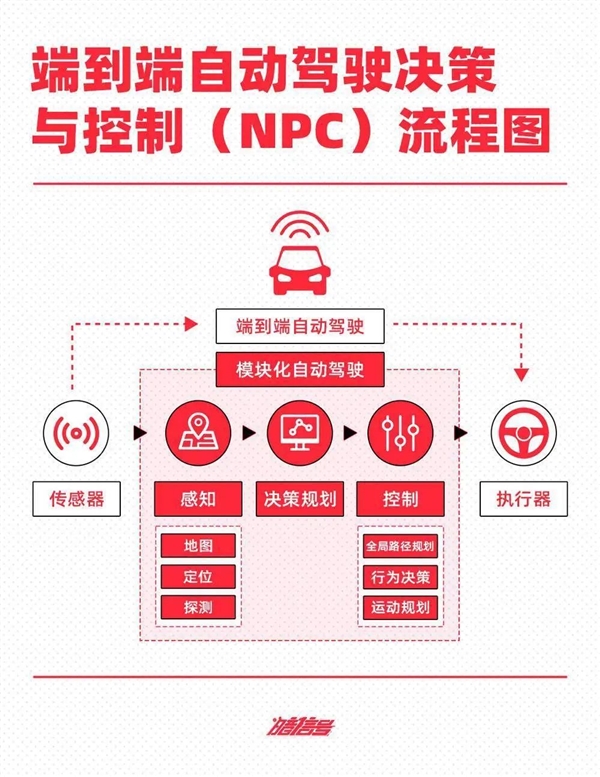
在模块化堆叠方法主导的时代,代码缺陷修复能力越强,智能驾驶的表现也越佳。然而,仅依靠传统智能驾驶规则难以根本解决现实世界的理解和推理难题,无法处理多种复杂场景和边缘案例。
因此,规则时代的局限性很快被大型模型和端到端方法的出现所取代,尤其是后者快速迭代的特性,吸引了许多车企投身于端到端技术,包括蔚来、小鹏、理想等品牌。
端到端已成为智能驾驶行业的下一代共识,尽管尚未有人能确定其是否能成为自动驾驶的终点,目前看来没有比端到端更优秀的智能驾驶技术解决方案。
鉴于此,本期内容旨在探讨市场上领先企业如何布局“端到端技术路线”,通过不同企业的策略和进展,揭示车辆智能驾驶能力的发展和未来竞争的关键点。
理想:双系统协同,“世界模型”外挂
理想汽车实际上是推行端到端路线的先锋。
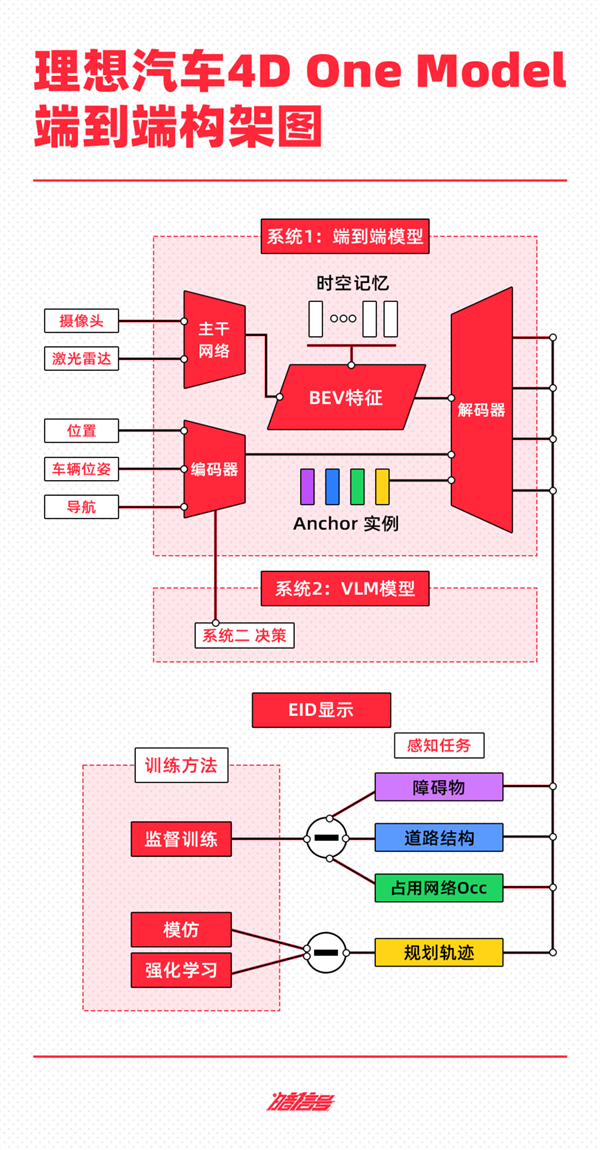
根据理想汽车公布的技术框架,其自动驾驶技术总共由端到端模型、视觉语言模型(VLM)和世界模型组成。
基于快慢系统理论,理想汽车构建了自动驾驶算法框架——
系统1通过One Model端到端模型实现,接收传感器信息并直接输出车辆行驶轨迹;
系统2则由VLM视觉语言模型完成,接收传感器数据后进行逻辑分析并将决策信息传递给系统1。
这两个系统的自动驾驶能力将在云端利用世界模型进行训练和验证。
端到端模型的输入主要来源于摄像头和激光雷达,通过CNN网络提取和融合多传感器特征,并将数据投影至BEV空间,叠加车辆状态和导航信息,通过Transformer模型进行编码解码,从而识别动态障碍物和道路结构,规划行车轨迹。
目前,系统1的训练数据集已有超过3亿个参数,使得该模型在实际驾驶中具备更高的通用障碍物理解和超视距导航能力。
系统2的VLM视觉语言模型主要关注5%的特殊交通场景,比如限行、潮汐车道等极复杂的交通规则,相当于副驾驶的教练实时监督驾驶行为,目前已有22亿参数。
VLM的工作方式为,将提示词文本编码为Tokenizer,然后将前视相机图像和导航地图进行视觉信息编码,最终通过模态对齐输出理解、决策和轨迹信息,传递给系统1以控制车辆。


